
| ||
Tue 2026-06-16
Mon 2026-06-15
Sun 2026-06-14
Queer Fascism and the End of Gay History Sat 2026-06-13
Fri 2026-06-12
Thu 2026-06-11
Wed 2026-06-10
Mon 2026-06-08
Search
Archives
2024
12 11 10 09 08 07 06 05 04 03 02 01
2023
2022
2021
2020
2019
2018
2017
2016
2015
2014
2013
2012
2011
2010
2009
2008
2007
2006
2005
2004
2003
One good site
MDN
Nelson Minar
Blog licensed under a Creative Commons License
|
A Twitter chat with Mark Fletcher reminds me that after years of trying, I finally have computer backups entirely sorted out. How’s your backup plan? Hard drives fail. And you need offsite backups too. Bad enough to contemplate your house burning down, but what if you lost all your data too? For local backup, Time Machine is amazing for Macs. I back up to an external 2.5” USB drive. The 2.5” part is important because it’s fully USB powered, no need for a power adapter. For my Linux box I use rsnapshot. I don’t have a recommendation for Windows. For remote backup, I am really happy with CrashPlan. There are many online backup products and most of them are bad. CrashPlan is good. It’s easy to configure, it’s very gentle on CPU and bandwidth, and they have lots of good restore options. Plenty of advanced features too; serious encryption, seeding by shipping a drive, even a free social backup. The Linux client is a little wonky but the consumer Mac client is fantastic. The price is reasonable, starting at $18/year. The one hurdle I’m still overcoming is what to back up. I still have more data than is reasonable to back up, particularly offline, so I have these backup sets that exclude ripped DVDs or whatever. Increasingly I’m thinking that’s a dangerous optimization and that I should just back up everything and stop worrying about it. Update: if you look around you can get a
10% discount on CrashPlan, as via
this link.
Is 2012 the last time the Summer Olympics will primarily be a television event? Will the Internet finally take over? On my desktop I’m flipping between Archery, Fencing, and Judo streaming live from NBC’s excellent live streaming site. Fourteen live sports; some fully produced, some unenhanced, all with decent camera work and live editing and 1080p streaming. And all enhanced by tweet streams, and articles, and background stories, and blessedly free of the inane chatter of sports personalities and stupid tape delays. If I missed something there’s archive; full events, highlights, analysis, whatever I want online. I can also watch live video with NBC’s iPad app or use the tablet to get extra info while watching the TV. It’s all pretty great, I don’t even mind having NBC as the intermediary. What’s missing from all this Internet viewing is the sense of a TV event, the whole family gathered around the electronic hearth watching something together. There’s still no great solution for playing Internet video on the big TV. It’s sort of doable as a hack but Internet-on-TV isn’t a mainstream thing, so it’s not a real product. Will it be by 2016? I sure hope so. But streaming the video is easy; the real problem is producing an event for Internet. The main program needs to be edited, boiling down 100 hours of a day’s events to a 3 hour program. But it also needs to preserve some of the liveness and variety that is the hallmark of web surfing. And then mix that together with Twitter so I can share the experience in real time with folks all over the world. Tall order. It’ll be interesting to see what emerges out of this year’s Olympics as media producers figure out how to integrate the Internet into event programming. I’m impressed with what NBC is delivering online this year but it feels transitional, like the very beginnings of something new. 
I’m one of those people who wake up at first light. In the summer when that’s 5:30am, it’s not so great. A simple sleep mask really helps in letting me get a proper sleep. There’s a zillion options, the key feature of this one is that it has little cups for your eyes so you can blink without brushing your eyelashes. Much less annoying that way. Tweetchive is a little hack I made to show various views of a user’s 3200 last tweets. The coolest thing is the map view, there are also buttons for text, pictures, and links. It’s not a complete product but I’m not sure if I’ll put more time into it and it’s useful enough to share. I was inspired to build this by All My Tweets. 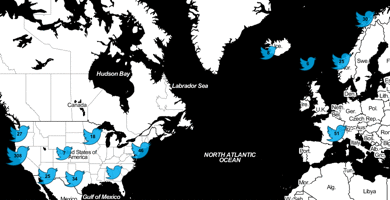 I made this because I write a lot on Twitter and wasn’t satisfied with their archive presentation. It’s awkward to find old tweets by text content. And the geodata is mostly invisible, there’s nothing like my map. So I used the API and built my own archive view! I launched this now because I fear this kind of hack will soon be harder to do. Twitter has signaled heavily for over a year that they’re uncomfortable with products that use the Twitter API to build competing clients. That stance makes some business sense but I worry they will make non-threatening projects like mine difficult. If Twitter puts more restrictions on the API I hope they do something else to make a person’s own tweets easily accessible to them (including old tweets). Twitter is the steward of our content, they owe us archival access. The implementation is a client-heavy Javascript app. My server just sends static HTML and Javascript. The browser does unauthenticated API fetches via JSONP and uses localStorage to cache data for repeat visits. The Javascript source is pretty readable if you’re curious. It’s remarkably fast despite being bloated and unoptimized. The key thing is none of the twitter.com traffic goes through my server, keeping everything very lightweight for me. Update July 24: the Twitter CEO has gone
on record
saying "We're working on a tool to let users export all of their tweets".
Disclosure: I have a financial interest in Twitter
My health insurance company Anthem fell afoul of the Affordable Care Act by paying themselves $1.3 million more than the allowed 20% overhead. So they are required to issue a rebate to individual ratepayers like me, a whopping 0.1% of my yearly premium. The accompanying letter is a masterpiece of passive-aggressive corporate communication. Check out my scan of the letter that shows up as page 2 of an invoice. All caps, monospace font, awkward formatting, it’s almost like they didn’t want us to read it! So I helped them out with this nicely formatted version. I typeset the letter for them but I didn’t correct the awkward grammar; such as inappropriate uses of commas, and the general awkward writing, such as extensive conjunctions. Typography aside the real offense is Anthem chose to cut a bunch of tiny checks to their customers rather than just applying the money as a premium rebate. Maybe they’re hoping a significant fraction of people won’t bother to deposit the $2 checks. Or maybe the inconvenience is just in keeping with their general contempt for their customers.  Yesterday’s leap second killed
half the Internet, including Pirate
Bay, Reddit,
LinkedIn,
Gawker
Media and a host of other
sites. Even an airline.
Any Linux user processes that depends on kernel threads had
a high chance of failing. That includes MySQL and many Java servers like
webapps, Hadoop, Cassandra, etc. The symptom was the user process spinning
at 100% CPU even after being restarted. A quick fix seems to be setting
the system clock which apparently resets the bad state in the kernel
(we hope).
Yesterday’s leap second killed
half the Internet, including Pirate
Bay, Reddit,
LinkedIn,
Gawker
Media and a host of other
sites. Even an airline.
Any Linux user processes that depends on kernel threads had
a high chance of failing. That includes MySQL and many Java servers like
webapps, Hadoop, Cassandra, etc. The symptom was the user process spinning
at 100% CPU even after being restarted. A quick fix seems to be setting
the system clock which apparently resets the bad state in the kernel
(we hope).
The underlying cause is something about how the kernel handled the extra second broke the futex locks used by threaded processes. Here’s a very detailed analysis on the failing code but I’m not sure it’s correct. According to this analysis the bug was introduced in 2008, then fixed in March 2012. But it may be the March fix is part of the problem. OTOH most of the systems that failed will be running kernels older than March so the problem must go further back. There's a kernel fix and also a detailed analysis. Time is hard, let’s go shopping. It’s frustrating that these bugs keep popping up; the theory is not so difficult. The NTP daemon tells the kernel a leap second is coming via adjtime(), the kernel should handle it by slewing or holding the clock, all is well. But it didn’t work in 2012. Didn’t work in 2009 either; a logging bug caused kernels to crash on the leap second. 2005 was better. Google’s solution of giving up on the kernel entirely and having the NTP daemon lie about what time it is seems more clever now. I got hit by this bug myself, the CrashPlan
backup daemon runs Java and got caught in a spin. And
none of my machines really kept time right because POSIX
does not account for leap
seconds. Both Ubuntu boxes just ran 23:59:59 twice, so time went
backwards on a subsecond basis. My Mac was even worse, it actually flipped
over to 00:00:00 before going backwards to 23:59:59 briefly. |
|

