
| ||
Fri 2025-07-18
Thu 2025-07-17
Wed 2025-07-16
Tue 2025-07-15
Mon 2025-07-14
Sun 2025-07-13
Fri 2025-07-11
Wed 2025-07-09
Tue 2025-07-08
Search
Archives
2024
12 11 10 09 08 07 06 05 04 03 02 01
2023
2022
2021
2020
2019
2018
2017
2016
2015
2014
2013
2012
2011
2010
2009
2008
2007
2006
2005
2004
2003
One good site
MDN
Nelson Minar
Blog licensed under a Creative Commons License
|
I got a cold recruiting email a few days ago from a notorious SMS
company that's oddly registered in Ascension Island. I normally
ignore this kind of recruiting mail, but this time around
I wrote back and
explained that because of what I'd heard about their unethical
business practices I wasn't interested in talking to them. (1, 2,
3.)
The recruiter must not have gotten my email because he called me. I explained again why I wasn't interested in talking with him and was shocked to hear an immediate response to the criticism that his company was unethical. Not "we're misunderstood" or "we've changed". No, he told me they were in a competitive market and couldn't worry about stepping on toes while building a business. I don't know what was more sad; the answer or the fact he had it at the ready. I'm reminded of this crazy story about it's like to work at a malware provider. Google has taken some knocks for its "don't be evil" policy. But the good thing is it immediately sets the internal debate at the right point. Not "can we get away with this" or "do we need to do this to build our business" but rather "is this right?" That's the place to start.
Amazon's new Elastic
compute cloud looks good. So many signups they've closed the
beta for now. Between EC2 for compute and
S3 for storage,
Amazon is offering most of a utility computing service. Store and process
data for very cheap, pay as you go. As a developer who recently lost access
to a massive compute farm I find these Amazon services very exciting.
Think of the startups it could enable!
But as the founder of a failed utility computing company I just don't get how Amazon's going to benefit from offering these services. The problem is the commodity pricing. If Amazon completely sells a server they gross about $900 a year. Say it costs $300 / year to buy and run a server and they fully sell out 10,000 machines, then Amazon nets $6M / year. Amazon made $360M last year, so this best case scenario would be a 2% earnings improvement. Nice, but worth the distraction to their primary business? I love that Amazon is offering this service; it seems very valuable and useful to people like me. But unless it's a long term viable business for Amazon it'd be foolish to build a product that relies on their service. I guess we'll see how it plays out. Sun's version of this was looking really bad last year, but then again the signup process at Sun is 1000 times harder. Thanks to waxy for
some chat on this question
Congratulations to the Flickr team for their new geotagging
interface. I think this is the first time it's truly easy
for normal people to indicate where they took their photographs in a
way others can benefit from.
It's a bit late for a pony request, but I sure wish geocoding interfaces had a notion of uncertainty along with location. Ie: latitude, longitude, and radius. A photo geocoded to "San Francisco, CA" is different from a photo geocoded to "659 Merchant St. San Francisco, CA". The former has a radius of about four miles. The latter, 20 feet. Tagging your photos via a map interface gives a natural radius: a few pixels' width in the map the user clicked on. GPS devices have a natural uncertainy measurement, too. So the data's available, why not store it? Update: A Flickr developer wrote to tell me that their
geotagging does store and use accuracy data. If you ask for
photos in a precise location you don't see photos that are too
general. Cool! Looks like its in the
API too.
Thanks to pb
for the term fuzzy geocoding
I posed a question about
embedding a subject URL in a request URL using percent encoding.
Thank you for all the helpful replies,
here's what I learned.
First, on the existential question, it seems in practice percent encoding really can create distinct names. Try: In reality this is just a quirk of Apache's handling of %2F, but since it's the default behaviour for the #1 web server out there that's a strong example. As for the theory, this wikipedia article claims that percent encoded reserved characters does create distinct names whereas percent encoded unreserved characters is just aliasing the same name. So escaping / would make a new name but escaping something like 0 wouldn't. Confusing, huh?As to the practical problem of PATH_INFO being unescaped basically everyone told me "yeah, CGI's a hack like that". So going with the hack I'll just use the REQUEST_URI variable Apache sets. It's not documented anywhere I can find but it seems to be an unadulterated literal copy of what the client requested, from which I can do careful parsing. For my service clients will need to know to percent-escape any / or ? in their URLs. And I'll just hope nothing else in the network decideds it's OK to unescape things on me. Some other suggested workarounds: length-delimit the subject URL so you know where it ends, have a magic string delimiting the end of the subject URL that you hope doesn't appear in any legitimate subject URL, or put the subject URL at the end of the request URL so that it ends where it ends. Any of these solutions could be made to work, I was just looking for the principle. Thanks to SethG, RyanB, MikeB, GregW, GordonM, and
SamR
A central reward in most MMOGs is leveling up. You play for a few
hours and then ding! you've gained a level. And a common
design feature in most games is that the higher your level, the more
time it will take to get to the next level.
The PlayOn folks have a nice graph of time to level in World of Warcraft as a function of level. I redrew it as level as a function of time. This view highlights the fact that your reward frequency diminishes over time. Early on it takes 2 hours of play to level up. But the rewards come more and more slowly to where you're playing 10 hours per "ding!". 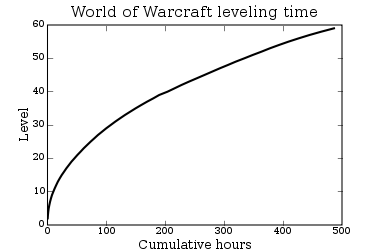 Maybe the time spent makes the rewards just seem more valuable? Level 60 feels like a big accomplishment given the time involved. But then, that's totally artificial. Or maybe the game developers cynically know they can get away with less frequent rewards because there's so much sunk cost. Players spend so much time getting to 44 that they'll spend longer for 45 because they're already invested.  The French for raccoon is raton laveur. Literally, the
"washing rat".
The French for raccoon is raton laveur. Literally, the
"washing rat".
The French for pie chart is camembert.
I need help. I'm building a REST-style web service. Its URLs specify
operations on other URLs, so I need to pass URLs as parameters to my
REST service. Let's say my service reverses the text of
whatever URL is specified.
http://example.com/rvs/someurl?a=b
The above request to my service means "return the contents of someurl reversed". To make things a bit
more complicated, there may be other stuff in my URLs after
someurl: the argument a=b in my example above.
So my question is, how do I correctly encode someurl? Let's say it's http://google.com/ I'm reversing. I'd think the request would contain a percent-quoted URL, something like
http://example.com/rvs/http%3A%2F%2Fgoogle.com%2F?a=b
However, the CGI
standard (and Apache2's implementation thereof) seems to be
decoding the URL before it gets to my application. Ie:
PATH_INFO contains
http://google.com/
not
http%3A%2F%2Fgoogle.com%2F
I can work around this
(REQUEST_URI isn't decoded), but something about all this
makes me uneasy. I'm relying on all web software between me and my
client to not mess with my carefully encoded URL. If the CGI standard
itself seems to think decoding is OK, who's to say some proxy or
browser won't too? Or to ask the question more existentially, do
these two URLs name the same resource? Or can they name different
things?
http://example.com/foo/bar
http://example.com/foo%2Fbar
Is there a good way to talk about URLs inside URLs? If you know the answer, mail me. I promise to share.  One of the highlights of our trip to Australia was
Tasmania. Tassie is quite different from mainland Australia; it's
very fertile
lush, mountainous, and cool. It's also wild and largely
unsettled. The whole west half of the island is covered in rugged mountains
rainforests, reminded me of the Olympic Peninsula.
One of the highlights of our trip to Australia was
Tasmania. Tassie is quite different from mainland Australia; it's
very fertile
lush, mountainous, and cool. It's also wild and largely
unsettled. The whole west half of the island is covered in rugged mountains
rainforests, reminded me of the Olympic Peninsula.
Hobart is the main town in Tasmania, but honestly it doesn't offer much to the tourist. But the nearby Port Arthur is fascinating; its the ruins of the last and most notorious prison of the Victorian era. We also took the five hour drive across the island to Strahan, a small tourist town (and former prison) on the west coast. The drive across was amazing, wild and empty roads with enormous forests. Absolutely beautiful. Strahan is the terminus of the West Coast Wilderness Railway to Queenstown, a mining town fascinating for its hideousness. The destination's not the point though; the trip itself is on a fantastically restored rack steam railway with beautiful engines that puffs up the rugged mountains through beautiful rainforests. Strahan is definitely worth a special trip, for either the first class package on the train or a boat trip up the rivers into the rainforests. You're at the end of nowhere and it's beautiful.
XML is bad for data transfer for lots of reasons. It's slow to parse,
awfully wordy, doesn't support 8 bit data, etc etc. But my favourite
thing is how most XML consumers can be induced to
open arbitrary URLs.
There's a 4+ year old security hole in many XML parsers called XXE, the Xml eXternal Entity attack. Take a look:
<?xml version="1.0" encoding="UTF-8"?>
Don't let all the pointy-parentheses confuse you (although they're a good
reason to hate XML too). What's going on there is my document has
defined
two new entities called passwd and http and then used
them. They're defined as expanding to the contents of URIs.
<!DOCTYPE doc [ <!ENTITY passwd SYSTEM "file:///etc/passwd"> <!ENTITY http SYSTEM "http://example.com/delAll"> ]> <eyeAmH4xor> &passwd; &http; </eyeAmH4xor> About 3/4 of the XML applications I've encountered out there will blindly do as ordered and load the URIs. The app will load the password file, at which point a clever hacker can usually induce the application to send it back to them (as an error message, for instance). Even better it will load the HTTP URL. Yes, many XML applications will load any URL you tell them to. From the app server. Nice, huh? XXE is an old bug, but it keeps coming back because most people using XML would never think their little XML parser can be instructed to start opening network sockets. Acrobat had this bug just last year. XML parsers usually have obscure options to secure them, but many have them off by default. Why are we using a data format where this is possible at all?
I'm working on a little webapp project. Usually I just use plain old
Python CGI scripts for these things but this time I actually care
about performance a bit so I did some delving into the modern world of
Python webapps. Things are a lot better than they used to be. WSGI is the
standard Servlet API, web.py (small) and Django (big) are good app
frameworks, and Zope is mercifully
sliding to retirement. But I'm stubborn and want to do things my own
way, just use FastCGI to avoid invocation overhead.
Turns out it's easy on a Debian system. Install the packages python-flup and libapache2-mod-fastcgi. Then write a python2.4 program like this:
#!/usr/bin/python2.4
import flup.server.fcgi g = 0 def app(environ, start_response): global g status = '200 OK' response_headers = [('Content-type','text/plain')] start_response(status, response_headers) g += 1 return ['Hello world! %d\n' % g] if __name__ == '__main__': from flup.server.fcgi import WSGIServer WSGIServer(app).run() The one badness is that modifying your Python code won't force a code reload, which sucks for development. If you name your program "foo.cgi" Apache will invoke it as normal CGI and Flup supports that too, so that's what I'll do for now. Even if it behaves differently.
I have about 300 photos from Australia I intend to edit and put online
before I leave for France. But as anyone who takes a lot of digital
photos will tell you, workflow is still a huge problem. Here's what I
do now:
A couple of folks wrote to suggest I try the Adobe
Lightroom beta. It's a lightweight photo workflow tool that combines an
image database with simple editing and printing tools. I like it,
particularly as a lightweight tool, and think it does 90% of what I do
with Photoshop only more easily. I'm looking forward to seeing this become
a real product, although it's hard to see how it will fit in with the
rest of Adobe's products.
About eight months ago I
moved my blog
to a new domain and set
up 301 redirects to point everyone to it. 301 means "moved
permanently": all bots should eventually stop hassling the old URL.
Does it work? Mostly; here's a list of hits in last week's traffic
from various bots.
A big part of online games is accumulating virtual wealth.
If you're lazy you can buy virtual money with real money, paying to
not play the game that you pay for.
I did a little study of the price of 1000 gold on 168 US Warcraft servers
and came up with some results.
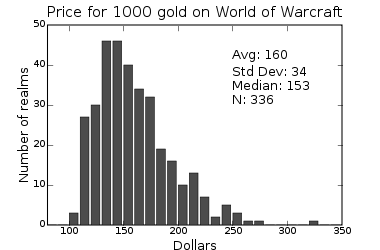 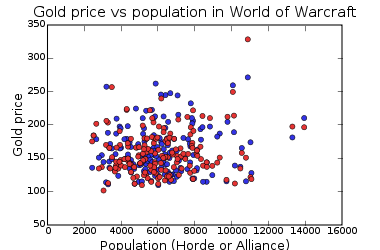 I got the price data from IGE and realm ages and populations from the WoW census. Update: one thing I did not appreciate is
how volatile gold prices are. Since writing the above two days ago IGE's median
price for 1000 gold went from $153 to $177! I'm collecting more data
both in time and from different gold merchants to understand this better.
Every six months or so I do a project that requires drawing graphs
from Python code. I usually use pygdchart
because it's easy and I know it but it's awfully primitive and ugly.
I've admired the output of matplotlib so I thought
I'd give it a try.
The 2d rendering is slow. I wrote a quicky program to generate a trivial graph with 4 points then render that plot to an image 10 times in a row. Depending on the backend it can take almost a second to render a graph! Here's the milliseconds it takes to render a single plot using each of the various matplotlib backends: GD: 440 Agg: 650 Cairo: 850 SVG: 60 PS: 90 There's also the no-op backend Template, 50ms. That's as fast as matplotlib is ever going to be. I'm disappointed by GD performance; it's not doing antialiasing or anything. Also surprised just how fast the SVG rendering is. I hope that's a viable publication mechanism some day; right now MSIE doesn't support it and Firefox misrenders it.
The AOL guys who published the search logs also wrote a
paper. The data download includes a
readme which says
Please reference the following publication when using this collection: G. Pass, A. Chowdhury, C. Torgeson, "A Picture of Search" The First International Conference on Scalable Information Systems, Hong Kong, June, 2006.That paper is readily online: Google search, ACM citation, author PDF download. The first author is Greg Pass, an AOL employee. Can't find a web page for him but here are some papers he's published. The second author is Dr. Abdur Chowdhury, "AOL Chief Architect for Research at AOL". Ouch. Third author is Cayley Torgeson of Raybeam Solutions. I gave the paper a quick read. It's an analysis of usage patterns of search engines: query frequencies, user behaviour, scalability requirements, etc. I didn't see any particularly surprising analysis but it's a summary of a lot of interesting hard-to-come-by data. I have a feeling that the AOL employees who released the search logs were honestly just trying to be good researchers and share their data. Only in this case they blew it. Now I feel a little bad for them. The goal of this collection is to provide real query log data that is based on real users. It could be used for personalization, query reformulation or other types of search research.
AOL released a bunch of its users search session data. A bit of looking
(1,
2,
3,
data,
NYT,
commentary)
is revealing just how much is in these logs.
Why hasn't AOL yet announced that the person responsible has been fired?
cannot sleep with snoring husbandI'm glad the leak happened; now everyone can see just how sensitive search data is. And valuable, too. Search logs are the private corporate property of companies like AOL to use (or misuse) as they want. Or for the US government to subpoena. Is that the best world for us? men like women with curvy bodiesWe're just at the beginning of the technology to mine the database of intentions. Thanks to AOL, now everyone can play along at home and try their hand at analysis.
My partner Ken and I will be living in Paris this fall. We've rented
an apartment for September through November and will be spending most
of our time in Paris itself, with occasional weekend trips around
France.
Ken and I have talked often about living in Europe, either full time or part time. We really enjoyed being in Zürich last fall but in the end decided it wasn't quite the city for us. We've spent enough time in France as tourists to know we like it, so time to take the next step of actually living there for awhile. If you're in Paris or think you may be visiting there sometime this fall, drop me a note!
One of the more odious-yet-legal businesses on the Internet is domain
squatting. Companies grab unused domain names and run pages of ads on
them. The less scrupulous ones also SEO the hell out of their crap ad
sites to get them up in search results. It's a hugely profitable
business, even Google has a product for domain squatters. But
it's ugly bottom-feeding.
However, sometimes it's funny. I present to you kitenwar.com. It's "for resources and information on Kitchenware and Iraq Iran War". The top 5 ads are labeled kitchenware, Iraq Iran war, cookware, war on terrorism, and cutlery. Some other related searches: depleted uranium and hairless cat. These particular ads seem to be coming from Yahoo/Overture. Not sure who owns the domain. What I was really looking for was kittenwar.com. Link to annoying sound I briefly embedded. For some reason no one seems to know about this program, so I'm writing about it again. The homepage is currently featuring a heartbreaking plea for donations so he can afford to buy a copy of Visual Studio 2005 and release a Unicode version of IZArc. If you happen to work in Microsoft dev relations maybe you can find a free copy to ship him?
I just got a laptop, so now I have the hell of
synchronizing multiple machines. Yes, 20 years after the
Network is the Computer I still can't transparently get from anywhere
to my data and software.
Google
Browser Sync is one tool to solve this problem. It syncs up your
Firefox settings, cookies, passwords, etc to a Google server. No
matter where you launch Firefox it will sync your data, in
theory giving you transparent access to browser state.
It mostly works, but it's got rough edges. Syncing is transparent and effective although I have mysteriously lost a couple of cookies. It syncs most of the data you care about except extensions and toolbar layout. Data is encrypted on the client, an essential feature. It's kind of ugly: the browser button is too big and it pops up annoying alerts if you run simultaneously on two machines. But there's one crippling flaw; it adds about five seconds of startup time everytime you launch Firefox. They must be getting a lot of complaint because it says right on the download page "we're working on it". Seems simple enough to fix, just don't sync every time. What I find most interesting about this is if you squint, Google Browser Sync looks a whole lot like another piece of Microsoft's Passport/Hailstorm vision. I have no idea what Google's planning in this area, but it seems obvious to me that people want to centralize a lot of personal data. Google's proven they can build products that scale and I'd trust them with my data more than any other company. More like this please! A couple of days after I put this on my weblog, Google
fixed the startup time problem.
In the early 1990s when Internet culture was coming together there was
a lot of excitement that we were creating a new space free from the
stupider rules and laws of our home countries. We even declared
independence. But now the Internet is far too vital to our world
economy and culture to remain free of traditional jurisdiction. But
the question remains: how do countries enforce rules on a space that
is both everywhere and nowhere?
The American approach is to extend its jurisdiction throughout the world. In the case of online gambling, by arresting people when they change planes in your country. David Carruthers (former CEO of BetOnSports) was arrested, held without bail, and charged with racketeering along with several of his staff. His company seems to have folded completely, promptly firing him and not appearing to support his not guilty plea. Countries need to enforce laws on the Internet. But of all the things the US could worry about, why online gambling? And nabbing people while they're in transit through your country seems awfully authoritarian. |
|

{kind=link}